
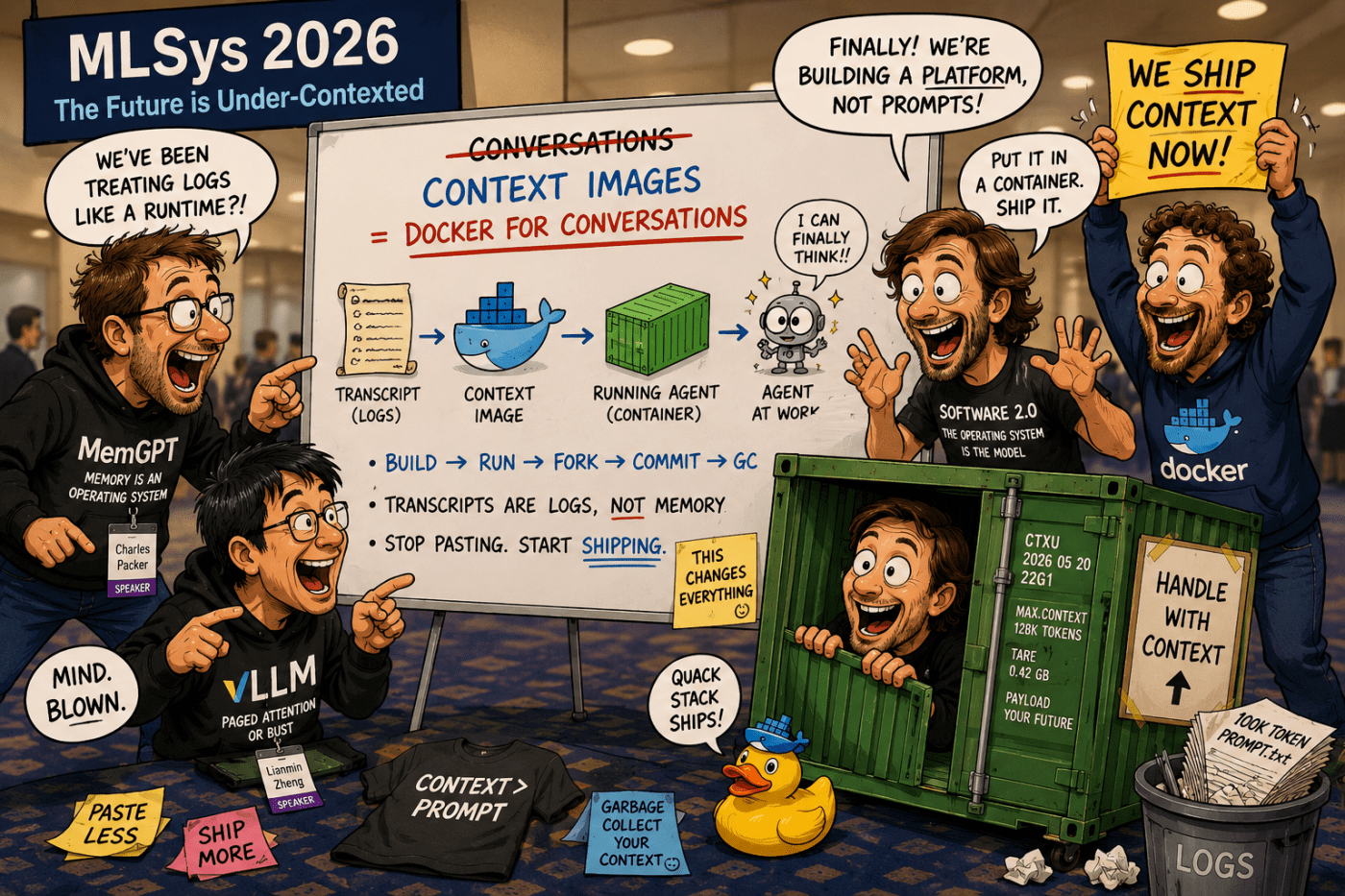
A sequel to WadTown Manifesto: The Miracle of Queryable Global Context.
At MLSys 2026, Charles Packer, Lianmin Zheng, Andrej Karpathy, and Solomon Hykes slowly realize they are all describing the same missing abstraction from different angles. Across fragmented hallway conversations and lossy retellings, the conference itself begins behaving like a distributed inference system. KV caches become compiled artifacts, agents become resumable runtimes, and transcripts become logs instead of memory. By the end, nobody remembers who first said wha, only that context images are Docker for conversations.
ChatGPT Prompt
SCENE 1 — COFFEE LINE
(Morning. Packer and Zheng waiting for espresso.)
Packer
The problem is that everyone treats conversations as transcripts instead of managed memory.
Zheng
The expensive part is recomputing KV state every request.
Packer
Right, because context windows are functioning like RAM.
Zheng
No, context windows are just the visible abstraction over attention locality.
Packer
…that’s basically memory management.
Zheng
It’s cache scheduling.
(Barista calls a name.)
Barista
“Charles?”
Packer
That’s me.
(He grabs coffee.)
Packer
Anyway, agents need virtual memory.
Zheng
We already built paging for KV blocks.
(They stare at each other briefly.)
Both
“Huh.”
(They leave in opposite directions.)
Blackout.
SCENE 2 — HALLWAY OUTSIDE “LLM SERVING AT SCALE”
(Late morning. Zheng runs into Karpathy.)
Karpathy
How’s the inference world?
Zheng
Everyone wants million-token contexts because they keep replaying conversations.
Karpathy
That feels architecturally wrong.
Zheng
It is. We should persist KV state directly.
Karpathy
So conversations are basically serialized process reconstruction.
Zheng
More or less.
Karpathy
Wait.
(He stops walking.)
Karpathy
Are we rebuilding working memory from logs every API call?
Zheng
Yes.
Karpathy
That’s horrifying.
Zheng
It’s stateless infrastructure.
Karpathy
No no no. That means chat history is just stdout.
(ZHENG laughs despite himself.)
Zheng
You sound like an operating systems person.
Karpathy
I think the industry accidentally became an operating systems field sometime last year.
(Beat.)
Zheng
Someone earlier told me agents need virtual memory.
Karpathy
That’s not even metaphorical anymore, is it?
(Conference volunteer interrupts.)
Volunteer
Panel starts in two minutes.
(They leave.)
Blackout.
SCENE 3 — SPEAKER DINNER
(Long table. Loud restaurant. Karpathy sitting beside Hykes.)
Hykes
So what are people obsessing over this year?
Karpathy
Context engineering.
Hykes
What does that mean?
Karpathy
Nobody knows.
(Beat.)
Karpathy
Officially it means prompts and retrieval.
Hykes
And unofficially?
Karpathy
Persistent cognitive runtimes with memory hierarchies and resumable inference state.
Hykes
…
Hykes
That just sounds like containers.
Karpathy
No, because these are conversations.
Hykes
Containers are also conversations. We just call them processes.
Karpathy
No, but these have memory and branching and checkpointing and resumability—
Hykes
So containers.
Karpathy
No, because they’re stochastic.
Hykes
So distributed systems.
(Long pause.)
Hykes
Wait. Are people replaying the entire conversation every request?
Karpathy
Yes.
Hykes
Why?
Karpathy
Because the APIs are stateless.
Hykes
That’s insane.
Karpathy
THANK YOU.
(Nearby attendees turn and stare.)
Hykes
Why don’t you snapshot runtime state?
Karpathy
Because the KV cache is architecture-specific and tied to tokenizer alignment and attention layout.
Hykes
Docker images are architecture-specific too.
(Silence.)
Karpathy
…
Hykes
…
Karpathy
Oh no.
Blackout.
SCENE 4 — HOTEL LOBBY, MIDNIGHT
(Packer typing furiously on laptop. Hykes enters carrying tea.)
Hykes
You’re the memory hierarchy guy.
Packer
That’s not what I said.
Hykes
Close enough.
Packer
I said agents need persistent working memory instead of replaying transcripts.
Hykes
Right. So why don’t you compile contexts into runnable artifacts?
Packer
Because contexts aren’t portable.
Hykes
Neither are containers.
Packer
…
Hykes
You rebuild from source when compatibility breaks.
Packer
…
Hykes
You HAVE source representations, right?
Packer
Transcripts. Retrieval indexes. Tool bindings. Memory stores.
Hykes
That’s a build context.
Packer
No, because—
(He stops.)
Hykes
You okay?
Packer
I think conversations are build logs.
(Long silence.)
Hykes
That sounds either very profound or deeply unhealthy.
Packer
Oh my god.
(He opens laptop again.)
Packer
Okay. Wait.
(Typing rapidly.)
Packer
Transcript equals source.
Hykes
Sure.
Packer
KV cache equals compiled artifact.
Hykes
Yep.
Packer
Running agent equals container.
Hykes
Obviously.
Packer
Context image.
Hykes
There it is.
Blackout.
SCENE 5 — AIRPORT SHUTTLE, FINAL MORNING
(All four accidentally end up together.)
Karpathy
Okay, apparently we’ve all been having the same conversation independently.
Zheng
Approximately the same conversation.
Packer
Lossily compressed.
Hykes
With poor cache locality.
(They nod.)
Karpathy
Let me see if I understand this.
(Counting on fingers.)
Karpathy
Conversations are not the runtime.
Zheng
Correct.
Karpathy
They are reconstruction artifacts for the runtime.
Packer
Yes.
Karpathy
The runtime is attention state plus tools plus working memory plus retrieval context.
Zheng
And KV locality.
Karpathy
Sure.
Karpathy
And the transcript is basically stdout.
Hykes
Exactly.
Packer
Which means agents are resumable cognitive containers.
Zheng
Backed by paged KV memory.
Karpathy
Compiled from conversational source code.
Hykes
Now you’re getting it.
(Silence.)
Shuttle Driver
You guys with the conference?
All Four
Yeah.
Shuttle Driver
What’s it about?
(Long pause.)
Karpathy
We think chatbots accidentally became operating systems.
(Driver nods like this explains nothing.)
Packer
No, no. Conversations are deployable runtime artifacts.
Zheng
No. Contexts are executable cache topologies.
Hykes
No. You reinvented Docker.
(Beat.)
Karpathy
Human conversation is just low-bandwidth distributed inference.
(Everyone goes quiet.)
Shuttle Driver
…
Shuttle Driver
So… computers?
Blackout.
Appendix I: Why These Four?
How did their past shape them for this epiphany?
Charles Packer arrives through memory.
His work on MemGPT frames LLMs as operating-system-like entities constrained by finite context windows, and proposes “virtual context management” inspired by hierarchical memory and paging. So he is primed to see the chat transcript not as the thing itself, but as an awkward mechanism for reconstructing a larger memory illusion.
Lianmin Zheng arrives through runtime pressure.
vLLM and PagedAttention treat the KV cache as the scarce, dynamic resource that makes LLM serving hard, borrowing virtual-memory ideas to manage KV blocks efficiently and share them across requests. So he is primed to see the “conversation” as less important than the underlying cache topology it induces.
Andrej Karpathy arrives through abstraction collapse.
His “Software 2.0” framing helped popularize the idea that neural networks are not just applications, but a new kind of software substrate; more recently, he has emphasized LLMs as a new computing platform. So he is primed to recognize when AI practice stops being prompt craft and starts becoming systems architecture.
Solomon Hykes arrives through artifact discipline.
Docker made the industry fluent in the distinction between source, image, running container, logs, volumes, registries, architecture tags, and rebuildability; Hykes is the person in the room most likely to hear “serialized, architecture-specific, resumable runtime environment” and ask why everyone is avoiding the word “image.”
Together, they form a clean four-part circuit: memory, cache, platform, container.
None of them needs to invent the whole idea alone; each only has to misunderstand the next person productively.
Appendix II: Why Docker?
Docker is the right analogy because it changed the unit of deployment.
Before Docker, people often talked about applications as if the source code was the thing. But in practice, the runnable thing was always larger. It included:
- dependencies
- filesystem layout
- environment variables
- startup commands
- architecture assumptions
- runtime permissions
- mounted volumes
- logs
Docker gave that whole messy bundle a name: an image.
Conversations have the same problem. A transcript looks like the thing, but the runnable thing is larger. It includes:
- system prompt
- tool schemas
- retrieval bindings
- memory state
- tokenizer state
- KV cache
- model fingerprint
- runtime layout
- continuation point
A context image names that bundle.
The Analogy Works Because Portability Has Constraints
Docker images are not magically portable. They are portable within explicit constraints. They depend on:
- architecture
- OS assumptions
- runtime compatibility
- rebuildable source
Context images would have the same shape. They are tied to:
- model
- tokenizer
- quantization
- position encoding
- attention layout
- runtime implementation
But they remain rebuildable from:
- transcript
- memory graph
- retrieval configuration
- tool bindings
- source documents
The Conceptual Mapping
Most importantly, Docker separated concepts that used to blur together:
- source tree / Dockerfile → transcript, memory graph, retrieval config
- image → serialized runnable context state
- container → live agent or inference process
- logs → chat transcript
- volumes → external memory and tools
- registry → shared context repository
The Real Insight
So “Docker for conversations” is not just a branding metaphor. It says the industry is using logs as runtimes, when it should be building, versioning, forking, running, and garbage-collecting context as infrastructure.
Appendix III: Context as Infrastructure
Once conversations become context images, context stops being prose and starts being infrastructure.
That means it needs infrastructure disciplines:
- build
- version
- cache
- fork
- inspect
- run
- mount
- garbage-collect
- rebuild
- audit
The Problem: Context as a Junk Drawer
Today, most AI systems treat context as a blob of text assembled at the last possible moment. The prompt becomes a junk drawer: instructions, examples, retrieved documents, user history, tool schemas, policies, scratchpad, and memory all crammed into one serialized message stream.
That works until the system becomes important.
That works until the system becomes important.
Then context needs the same maturity we expect from deployment artifacts. You need to know:
- what source material produced this context
- which model and tokenizer it was built for
- which tools were mounted
- which memory stores were included
- which retrieval indexes were used
- what changed since the last run
- whether the image can be rebuilt
- whether two images share layers
- whether a branch can be resumed
The Shift: From Prompting to Context Operations
This is the shift from prompting to context operations.
A mature context system would treat the transcript as only one input among many. The runnable context might be assembled from:
- system instructions
- user preferences
- project memory
- relevant documents
- tool definitions
- retrieval indexes
- prior decisions
- active task state
- KV cache layers
- runtime metadata
The context image is the compiled artifact. The live agent is the running process. The transcript is the log.
The context image is the compiled artifact. The live agent is the running process. The transcript is the log.
That separation matters because it makes context governable. Teams could review context diffs, pin versions, reproduce failures, roll back bad memories, share known-good images, and isolate experimental branches.
Reusable Context Layers
It also makes context reusable. Instead of rebuilding the same expensive working set for every conversation, a system could maintain durable layers:
- base assistant behavior
- organization knowledge
- project state
- customer state
- active incident state
- personal working memory
Each layer could be rebuilt from source, cached when hot, invalidated when stale, and forked when exploration begins.
This is what “context as infrastructure” means: not better prompts, but better lifecycle management for the state that makes intelligence useful.
Appendix IV: The Context Image Spec v1.0
A Context Image is a rebuildable, runnable artifact for continuing an AI interaction from a known state.
- It is not a chat transcript.
- It is not a memory database.
- It is not a model checkpoint.
- It is not merely a prompt.
It is the compiled form of a context environment.
A Context Image contains enough information for a compatible runtime to resume, fork, inspect, or rebuild an active cognitive process.
1. Core Definition
A Context Image is composed of three layers:
- source
- compiled state
- runtime manifest
The source is the human-readable and rebuildable material from which the context was created.
The compiled state is the optimized runtime representation, such as KV cache blocks, prefix-cache layers, retrieval bindings, tool schemas, and active working memory.
The runtime manifest explains what the image is, how it was built, what it depends on, and where it may safely run.
The source is canonical.
The compiled state is disposable.
The manifest is the contract.
2. Required Manifest Fields
Every Context Image must declare:
- image name
- image version
- creation timestamp
- parent image, if any
- source hash
- model fingerprint
- tokenizer fingerprint
- runtime fingerprint
- context length
- position encoding configuration
- quantization or precision format
- KV cache layout
- tool schema version
- retrieval configuration
- memory mounts
- security policy
- rebuild instructions
A runtime may refuse to load a Context Image if any required compatibility field does not match.
This is not a failure of portability.
This is honest portability.
3. Source Bundle
The source bundle should contain the rebuildable ingredients of the image.
These may include:
- system instructions
- developer instructions
- user instructions
- chat transcript
- summarized history
- project memory
- user preferences
- source documents
- retrieval indexes
- tool definitions
- environment variables
- policy constraints
- previous decisions
- active task state
The source bundle should be inspectable, diffable, and versionable.
A Context Image without a source bundle is only a snapshot.
A Context Image with a source bundle is infrastructure.
4. Compiled State
The compiled state may contain runtime-specific artifacts.
These may include:
- serialized KV cache blocks
- prefix-cache layers
- attention-position metadata
- tokenized prompt segments
- embedding handles
- retrieval cache entries
- tool-call state
- working-memory slots
- branch lineage
- scheduler hints
- cache locality hints
Compiled state is allowed to be architecture-specific.
It may depend on:
- model weights
- tokenizer
- quantization
- runtime implementation
- attention layout
- GPU architecture
- CPU architecture
- cache allocator
- block size
- position encoding scheme
A Context Image runtime should treat compiled state as an optimization, not as the source of truth.
If compiled state is invalid, stale, corrupt, or incompatible, the runtime should attempt to rebuild it from source.
5. Layers
A Context Image may be layered.
Each layer represents reusable context.
Common layers include:
- base model behavior
- organization context
- team context
- project context
- customer context
- task context
- incident context
- personal working memory
- active continuation state
Layers should be immutable once published.
Mutable state should live in a writable top layer.
This enables:
- reuse
- branching
- cache sharing
- incremental rebuilds
- rollback
- provenance tracking
- garbage collection
A good Context Image system should avoid duplicating expensive lower layers when forking.
6. Lifecycle Operations
A Context Image runtime should support the following operations:
- build — Construct a Context Image from source material.
- run — Start a live inference process from an image.
- resume — Continue from a saved image state.
- fork — Create a branch from an existing image.
- commit — Save the current runtime state as a new image.
- inspect — Show manifest, lineage, source hashes, mounted tools, and memory dependencies.
- diff — Compare two images by source, manifest, memory, or transcript.
- rebuild — Regenerate compiled state from canonical source.
- evict — Remove compiled state while preserving source.
- gc — Remove unreachable layers and unused cache blocks.
- export — Package source and manifest for another environment.
- import — Load an image, validating compatibility before execution.
The minimal viable runtime supports:
- build
- run
- fork
- commit
- rebuild
- inspect
Everything else is polish.
7. Compatibility
A Context Image is compatible with a runtime only if the declared execution environment matches.
Compatibility should be checked against:
- model family
- exact model weights
- tokenizer
- vocabulary
- chat template
- context length
- RoPE or position encoding
- quantization
- attention implementation
- KV layout
- tool schema
- memory API
- retrieval API
- safety policy
The runtime must distinguish between:
- source-compatible
- rebuild-compatible
- binary-compatible
- runtime-compatible
For example:
- A transcript may be source-compatible across many models.
- A tokenized prompt may be rebuild-compatible only with the same tokenizer.
- A KV cache may be binary-compatible only with the same model and runtime.
- A live continuation may be runtime-compatible only on the same local machine.
This distinction prevents false portability.
8. Runtime Identity
A running Context Image is not the same thing as the image itself.
The image is the artifact.
The running process is the instance.
A single image may produce many live instances.
Those instances may:
- diverge
- branch
- mutate working memory
- call different tools
- produce different transcripts
- commit different descendants
The transcript belongs to the instance.
The lineage belongs to the image.
The memory writes belong to the mounted volumes.
9. Logs and Transcripts
A transcript is a log.
It may be used for:
- audit
- replay
- debugging
- rebuilding
- human review
- summarization
- provenance
But the transcript is not the runtime.
The runtime includes state that may not appear directly in the transcript, including:
- cached attention state
- tool handles
- retrieval bindings
- active memory mounts
- hidden scheduler state
- unresolved continuations
- branch ancestry
A mature system should preserve transcripts, but should not confuse them with executable context.
10. Memory Mounts
Context Images may mount external memory.
Memory mounts may be:
- read-only
- read-write
- ephemeral
- persistent
- local
- remote
- user-scoped
- project-scoped
- organization-scoped
Examples include:
- vector databases
- document stores
- file systems
- knowledge graphs
- issue trackers
- code repositories
- user preference stores
- tool histories
- prior decision logs
A Context Image should record what memory was mounted, but should not necessarily copy all mounted memory into the image.
The image contains bindings.
The mount contains data.
11. Security and Audit
A Context Image may contain sensitive state.
It may encode information in:
- transcripts
- summaries
- retrieved documents
- memory handles
- tool results
- KV cache blocks
- embeddings
- latent continuation state
Therefore, a runtime should support:
- manifest inspection
- source inspection
- redaction
- access control
- signature verification
- provenance tracking
- policy validation
- encrypted storage
- safe export modes
- compiled-state eviction
A Context Image registry should not accept opaque runtime blobs without source, provenance, or compatibility metadata.
Opaque snapshots are convenient.
Auditable images are infrastructure.
Opaque snapshots are convenient.
Auditable images are infrastructure.
12. Rebuild Semantics
Every serious Context Image should answer one question:
Can this image be rebuilt from source?
A rebuildable image should declare:
- source files
- source hashes
- build order
- model dependency
- tokenizer dependency
- retrieval dependency
- memory dependency
- tool dependency
- build parameters
- deterministic settings, where available
Rebuilding may not reproduce stochastic outputs exactly.
But it should reproduce the runnable context environment closely enough to continue, inspect, debug, or validate the process.
The goal is not perfect determinism.
The goal is operational trust.
13. Branching
Forking is a first-class operation.
A forked Context Image should preserve:
- parent image reference
- fork timestamp
- inherited layers
- modified top layer
- transcript divergence point
- memory write policy
- compatibility metadata
Branches should be cheap when lower layers are shared.
The runtime should support copy-on-write behavior for:
- KV cache blocks
- working memory
- retrieved context
- tool state
- transcript logs
Merging branches is not required in v1.0.
Summarizing branches is allowed.
Diffing branches is encouraged.
Pretending semantic merge is solved is forbidden.
14. Example Manifest
schema: context-image/v1.0
name: quilt/customer-review
version: 2026.05.22
created_at: 2026-05-22T09:30:00-07:00
parent: quilt/base-engineering:2026.05
source:
transcript: transcript.jsonl
memory_graph: memory.yaml
retrieval_config: retrieval.yaml
tools: tools.yaml
source_hash: sha256:...
model:
name: llama-3.1-8b-instruct
weights_hash: sha256:...
tokenizer_hash: sha256:...
chat_template_hash: sha256:...
context_length: 131072
position_encoding: rope
runtime:
engine: llama.cpp
engine_version: ...
kv_layout: contiguous-v1
quantization: q4_k_m
compatible_arch:
- arm64
- x86_64
compiled_state:
kv_cache: kv.bin
token_prefix: tokens.bin
prefix_layers:
- base-assistant
- quilt-engineering
- customer-review
mounts:
memory:
- name: project-memory
mode: read-write
retrieval:
- name: docs-index
mode: read-only
tools:
- name: file-search
- name: shell
policy:
exportable: false
allow_compiled_state_export: false
allow_source_export: true
redact_on_export:
- secrets
- credentials
- private_documents
rebuild:
command: ctx build .
deterministic: partial
15. Example CLI
ctx build .
ctx inspect quilt/customer-review
ctx run quilt/customer-review
ctx fork quilt/customer-review quilt/customer-review-alt
ctx commit quilt/customer-review-alt:v2
ctx diff quilt/customer-review quilt/customer-review-alt
ctx evict quilt/customer-review --compiled-state
ctx rebuild quilt/customer-review
ctx gc
The CLI should make the distinction obvious:
ctx buildcreates an imagectx runcreates an instancectx commitsaves an instance as a new imagectx evictdeletes acceleration statectx rebuildreconstructs acceleration state from source
16. Non-Goals for v1.0
Context Images v1.0 does not attempt to solve:
- universal portability
- semantic branch merging
- cross-model KV translation
- deterministic replay of stochastic generations
- safe sharing of arbitrary opaque caches
- replacing transcripts
- replacing memory systems
- replacing model checkpoints
- replacing agent frameworks
The goal is narrower:
Define the missing artifact between transcript and runtime.
17. The One-Sentence Spec
A Context Image is a rebuildable, architecture-aware, runnable artifact that packages the state needed to continue an AI interaction, while preserving a clean separation between source, compiled context, live instance, and transcript log.
