
…the full, messy, contradictory, human context / can be made visible enough that / people can act within it intelligently…
WadTown Manifesto: The Miracle of Queryable Global Context

…the full, messy, contradictory, human context / can be made visible enough that / people can act within it intelligently…
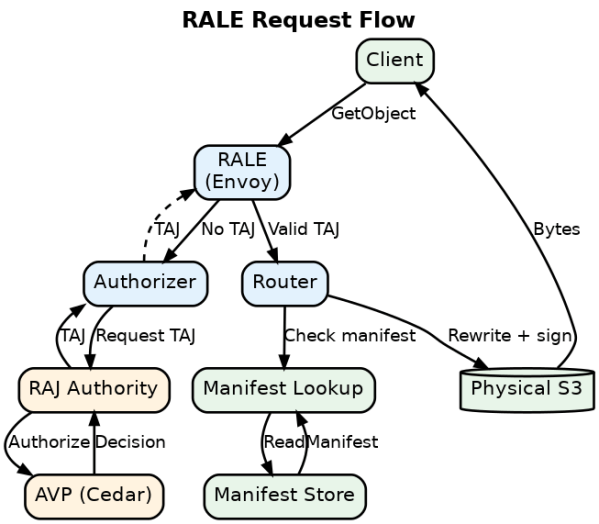
Clients shouldn't know bucket names, regions, or AWS accounts Access should be fine-grained (specific packages, not entire buckets) Authorization should be efficient (not re-evaluated per file) Data locations should change without breaking client code Traditional S3 approaches fail...

Explain how SDA is like being able to “eat the menu;” as a Roald Dahl story.

“What’s missing is the thing we had for structured data. But for… all of this.”

To enable all people to create, transmit, and preserve knowledge in ways that remain freely chosen, universally accessible, resistant to domination, and aligned with truth and integrity.

A cooperative, distributed means for creating, propagating, and safeguarding knowledge through minimal agreements, mutual trust, and maximal autonomy.

The MCG integrates data trust, intent modeling, and semantic negotiation into a shared cognitive substrate. It supports not just interoperability—but mutual understanding.

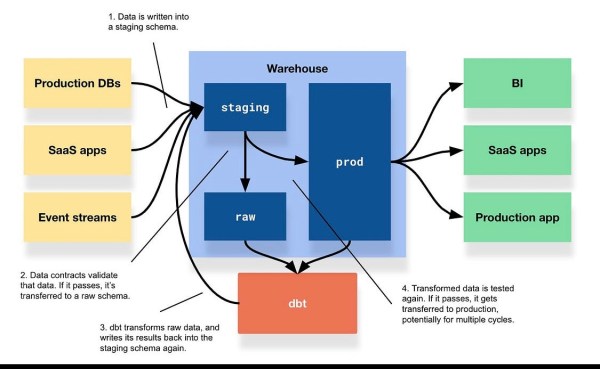
Fractal Data Lakehouse merges the scalable raw data capabilities of a data lake with the structured analytical power of a data warehouse, governed by fractal principles—recursive, self-similar patterns across space (geography), time (history), and people (identity).
The profound truth here is that we cannot control other people. We can only honestly and gracefully fail, if we are not getting what we need to succeed.
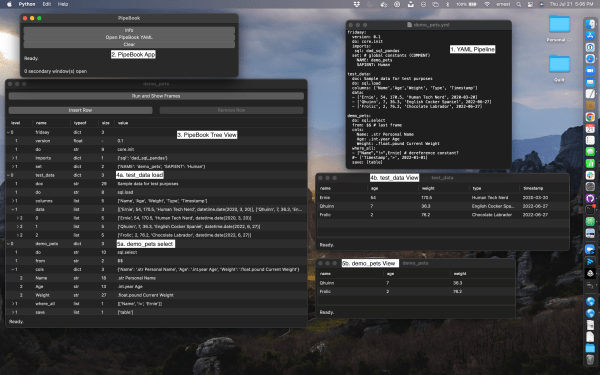
A key design goal of PipeBook is to break away from the single-browser-window user experience of traditional data notebooks, to take full advantage of the large screens on today's laptops and desktops. The PipeBook Multi-Window User Experience (Live prototype, annotated) Windows In particular, a single PipeBook "document" consists of: The Pipe window, which can toggle... Continue Reading →

You must be logged in to post a comment.