
A cooperative, distributed means for creating, propagating, and safeguarding knowledge through minimal agreements, mutual trust, and maximal autonomy.
Unbreakable Knowledge: A Chaordic Manifesto

A cooperative, distributed means for creating, propagating, and safeguarding knowledge through minimal agreements, mutual trust, and maximal autonomy.

The MCG integrates data trust, intent modeling, and semantic negotiation into a shared cognitive substrate. It supports not just interoperability—but mutual understanding.

Data mesh was never about tools. It’s about rethinking responsibility and trust in a data-driven world. With MROW in IceMesh, we get: - Sovereign data products / - Federated evolution / - Global interoperability through local clarity

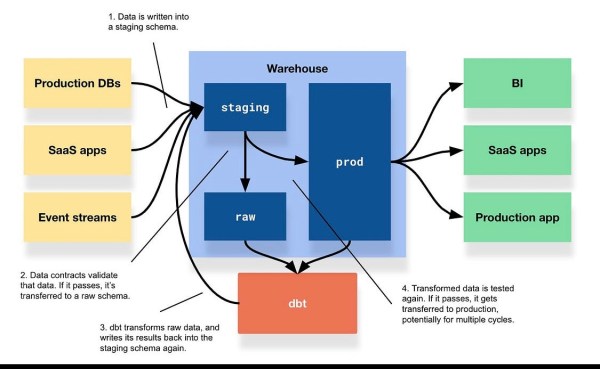
Fractal Data Lakehouse merges the scalable raw data capabilities of a data lake with the structured analytical power of a data warehouse, governed by fractal principles—recursive, self-similar patterns across space (geography), time (history), and people (identity).

Custodial AI is a human-aligned artificial intelligence entrusted with the ongoing care and semantic coherence of a digital artifact, institution, or system—ensuring it continues to reflect and serve the long-term intent of its human stakeholders.

came of age in the 1980s, as the C programming language and UNIX operating system were becoming the gold standard for "serious" computing. I was taught that: - Lisp reflects how computers **think** - C reflects how computers **work** - Shell scripts reflect how humans **write** I never questioned this split ....

Mark Burgin: Saul! I just finished reading about Homoiconic C and its concept of “named frames.” It struck me as an interesting middle ground between my named set theory and your pure data foundation. What’s your take on it?

By drawing on Littoral Science, Littoral Ethinomics offers a path to reintegrate ethics into economics. With AI as a mediator, we can move beyond transactional models to systems that optimize both for efficiency and ethical values. As AI continues to reshape industries, Littoral Ethinomics provides the framework for an economy that fosters human flourishing, social trust, and sustainability. This evolution signals a new era in economic thought, where technology serves not just the market but also humanity.
### Alan Turing Here’s a simple breakdown: **Shannon Machines:** - Start with data structures, with computation as secondary. - Focus on associative memory and managing state. - Use binary operators and bit transforms for math simulation. **Turing Machines:** - Start with basic arithmetic and build up to computation. - Provide a theoretical framework, independent of practical implementation. - Use algorithms to simulate any computing process.
The profound truth here is that we cannot control other people. We can only honestly and gracefully fail, if we are not getting what we need to succeed.

You must be logged in to post a comment.